Python 200 Interview Questions and Answers for Experienced in 2025
Are you preparing for advanced Python interviews in 2025? Our 200 Python Interview Questions and Answers for Experienced in 2025 have been carefully collected from top MNC companies, ensuring you practice the exact type of questions asked in real interviews. These questions cover advanced Python concepts like OOPs, decorators, multithreading, data structures, memory management, error handling, web frameworks (Django, Flask), APIs, machine learning integration, and cloud deployment.
At MyLearnNest Training Institute, these Python interview questions and answers have been designed by expert trainers who understand industry requirements. The content is prepared with a mix of coding challenges, scenario-based questions, and real-world problem-solving approaches that companies expect from experienced developers.
Python continues to dominate the IT industry with applications in AI, Data Science, Web Development, Automation, and Cloud Computing. That’s why recruiters focus on deep technical knowledge and practical coding skills. By practicing these 200 Python Interview Questions and Answers, you can gain confidence to clear technical rounds and coding interviews with ease.
MyLearnNest ensures its students stay industry-ready with structured interview preparation, real-time projects, and job-oriented training. Whether you’re aiming for roles like Python Developer, Data Engineer, AI Engineer, or Automation Expert, these resources will help you crack interviews in leading companies.
Python Training in Hyderabad – MyLearnNest Training Academy
MyLearnNest Training Academy offers the best Python Training in Hyderabad, designed to prepare learners with practical coding skills and real-world project experience. This comprehensive program covers Core Python, Advanced Python, Object-Oriented Programming (OOPs), Data Structures, Exception Handling, File Handling, Web Frameworks (Django, Flask), REST APIs, Data Science with Python, and Automation.
Learners gain hands-on experience with live coding sessions, mini-projects, and industry case studies. You will master Python applications in Web Development, Data Science, Machine Learning, Automation, and Cloud Computing, making you job-ready for multiple domains.
This training is ideal for students, IT professionals, developers, data analysts, and business leaders who want to upskill in one of the most in-demand programming languages. The curriculum also includes integration with databases (MySQL, MongoDB), cloud deployment (AWS, Azure, Google Cloud), and automation scripts.
MyLearnNest provides flexible learning options (online, offline, and self-paced), along with 100% placement assistance, resume building, and mock interview preparation. Upon completion, learners receive an industry-recognized Python certification, opening opportunities for roles such as Python Developer, Data Scientist, Automation Engineer, and AI Engineer.
With lifetime course access, expert mentorship, and continuous Python updates, learners always stay ahead in the IT industry. MyLearnNest ensures practical, job-oriented training that helps you build a strong career in Python programming.

200 Python Interview Questions and Answers for Experienced in 2025 Collected from TOP MNCs
- What are Python’s key features?
Python is a high-level, interpreted programming language known for its simplicity and readability. It supports multiple programming paradigms, including procedural, object-oriented, and functional programming. Python’s extensive standard library and vibrant community make it versatile for various applications like web development, data science, automation, and AI. Its dynamic typing and automatic memory management simplify coding tasks. Python also has strong support for integration with other languages and tools. Overall, Python’s clean syntax and powerful capabilities have made it one of the most popular languages today.
- How is memory managed in Python?
Memory management in Python is handled by the Python memory manager, which manages the allocation of private heap space for Python objects and data structures. The core of memory management is the reference counting technique, where every object keeps track of how many references point to it. When the reference count drops to zero, the memory is deallocated. Additionally, Python has a built-in garbage collector to handle cyclic references that reference counting alone can’t resolve. This combination ensures efficient memory use and automatic cleanup of unused objects. Programmers don’t need to manually allocate or free memory, which helps avoid memory leaks.
- Explain Python’s Global Interpreter Lock (GIL).
The Global Interpreter Lock, or GIL, is a mutex that protects access to Python objects, preventing multiple native threads from executing Python bytecodes simultaneously. This means that even in a multi-threaded Python program, only one thread can execute Python code at a time, limiting true parallelism in CPU-bound tasks. The GIL simplifies memory management and avoids race conditions but can be a bottleneck for CPU-intensive operations. To overcome this, Python developers often use multiprocessing or external libraries that release the GIL during heavy computation. Despite its limitations, the GIL is crucial for Python’s thread safety in many implementations.
- What are Python decorators and how do they work?
Decorators in Python are a powerful feature that allows modification of functions or methods using other functions, often used to add functionality dynamically. A decorator is a function that takes another function as input and returns a new function with added behavior, without changing the original function’s code. They are commonly used for logging, access control, memoization, or instrumentation. Decorators use the @decorator_name syntax above function definitions for cleaner code. Internally, the decorator wraps the original function, allowing pre- and post-processing during calls. This feature promotes code reuse and separation of concerns in Python programs.
- How does Python handle exceptions?
Python uses a try-except block to handle exceptions gracefully, preventing abrupt program crashes. Code that might raise an exception is placed inside the try block, and corresponding except blocks catch specific exceptions to handle them appropriately. Python supports multiple exception types, enabling granular error management, and you can also create custom exceptions. The finally block, if used, executes code regardless of whether an exception occurred, useful for cleanup. Raising exceptions explicitly with the raise keyword allows signaling error conditions. This structured approach promotes robust and maintainable error handling in Python applications.
- What are Python’s generators and how do they differ from functions?
Generators are special functions that return an iterator and produce values lazily using the yield statement instead of return. Unlike regular functions that run entirely and return a single value, generators pause execution at each yield and resume from there on the next call. This lazy evaluation saves memory when handling large datasets or infinite sequences since values are generated on demand. Generators are ideal for streaming data or pipeline processing, as they provide efficient iteration without loading everything into memory. They also help in writing cleaner asynchronous and coroutine code. Overall, generators optimize performance in resource-constrained scenarios.
- What is the difference between lists and tuples in Python?
Lists and tuples are both sequence data types in Python, but lists are mutable, meaning you can modify, add, or remove elements after creation. Tuples, on the other hand, are immutable; once created, their contents cannot be changed. Because of immutability, tuples are generally faster and can be used as dictionary keys. Lists have more built-in methods for modification, whereas tuples provide data integrity when you want fixed data. Use tuples for read-only data and lists when you expect to change the data. This distinction helps optimize performance and maintain code safety.
- How does Python’s list comprehension work?
List comprehensions provide a concise and readable way to create lists by embedding loops and conditional statements inside square brackets. Instead of using verbose loops, you can generate new lists by applying an expression to each item in an existing iterable. They support filtering elements with conditions, making code shorter and often faster. For example, [x*2 for x in range(5) if x % 2 == 0] doubles only even numbers from 0 to 4. List comprehensions enhance clarity and efficiency, making them a preferred Pythonic way to manipulate lists. They can also be nested for more complex transformations.
- Explain the difference between is and == in Python.
The == operator checks if the values of two objects are equal, meaning their contents are the same. In contrast, the is operator checks for object identity, meaning whether both variables point to the exact same object in memory. For example, two different lists with identical contents will be equal using ==, but not the same using is. This distinction is crucial when dealing with mutable objects or singletons like None. Using is is preferred when you want to check if something is None or verify object identity, while == compares the actual data stored.
- What are Python’s built-in data types?
Python includes several built-in data types such as numeric types (int, float, complex), sequences (list, tuple, range), text (str), sets (set, frozenset), and mappings (dict). Additionally, Python has Boolean (bool) and binary types (bytes, bytearray, memoryview). These types cover a wide range of programming needs and can be combined or subclassed for custom data structures. Each type has its own methods and behaviors that make Python flexible and powerful. Understanding these types is fundamental for effective programming and efficient memory management.
- How do you manage packages and dependencies in Python?
Python uses package managers like pip to install and manage third-party libraries from the Python Package Index (PyPI). Virtual environments (venv or tools like virtualenv) are used to create isolated spaces where project dependencies are installed separately, avoiding conflicts between projects. This approach ensures consistent environments across development, testing, and production. Tools like requirements.txt files help specify exact package versions for reproducibility. Modern dependency managers like poetry provide more advanced features such as version resolution and packaging. Proper dependency management is essential for scalable and maintainable Python projects.
- What is the difference between deep copy and shallow copy?
A shallow copy creates a new object but inserts references to the objects found in the original, meaning changes in nested mutable objects affect both copies. Deep copy, however, recursively copies all nested objects, producing a fully independent clone with no shared references. Python’s copy module provides copy() for shallow copies and deepcopy() for deep copies. Choosing between them depends on whether you want changes in nested structures to reflect in the copy. Shallow copies are faster but risk side effects, while deep copies ensure complete data isolation but are more resource-intensive.
- How can you improve Python code performance?
Improving Python performance involves techniques such as using built-in functions and libraries optimized in C, leveraging list comprehensions over loops, and minimizing global variable usage. Profiling tools like cProfile help identify bottlenecks. For CPU-bound tasks, multiprocessing can bypass the GIL by running code in parallel processes. Using just-in-time compilers like Numba or alternative interpreters like PyPy also speeds execution. Avoiding unnecessary memory allocation and employing efficient algorithms significantly impact performance. Profiling combined with targeted optimizations yields the best results.
- What are Python’s lambda functions?
Lambda functions are anonymous, small functions defined using the lambda keyword, typically for simple operations. They can have any number of arguments but only a single expression, which is implicitly returned. Lambdas are often used for short, inline functions passed as arguments to higher-order functions like map(), filter(), and sorted(). They improve code brevity but should be used judiciously for clarity. For more complex operations, defining regular functions with def is recommended. Lambdas are a concise way to write small, throwaway functions quickly.
- What are Python’s comprehensions and how many types exist?
Python comprehensions provide a succinct way to construct sequences, including lists, dictionaries, and sets, from iterables. The three main types are list comprehensions ([]), dictionary comprehensions ({key: value}), and set comprehensions ({}). All of them support conditions and expressions inside a compact syntax. These constructs replace longer loops and conditionals, making the code more readable and often more efficient. They also support nesting and multiple loops. Comprehensions are a hallmark of Pythonic coding style and are widely used for data transformation tasks.
- What is the difference between @staticmethod and @classmethod?
Both @staticmethod and @classmethod are decorators that define methods inside classes but differ in their behavior. A static method does not receive any implicit first argument; it behaves like a regular function inside a class namespace and can’t access class or instance data. A class method receives the class (cls) as the first argument, allowing it to access or modify class state. Class methods are often used as alternative constructors or methods affecting the class as a whole. Static methods group functions logically inside classes without depending on class or instance data.
- How does Python handle variable scope?
Python uses the LEGB rule to resolve variable scope: Local, Enclosing, Global, and Built-in. Variables declared inside a function are local and accessible only within that function. Enclosing refers to variables in any enclosing functions for nested functions. Global variables are declared at the module level and accessible throughout the module. Built-in scope includes Python’s predefined names. When referencing a variable, Python searches in this order until it finds the variable. Understanding scope helps prevent naming conflicts and bugs in complex codebases.
- What are Python’s iterators and iterables?
An iterable is any Python object capable of returning its members one at a time, such as lists, tuples, or strings. An iterator is an object that implements the __next__() method to return the next item and raises StopIteration when no more items are left. Iterables provide an __iter__() method which returns an iterator. You can loop over any iterable using a for loop, which internally uses an iterator. This protocol allows Python to handle large datasets efficiently and supports custom iteration patterns. Iterators and iterables are fundamental to Python’s looping mechanisms.
- Explain Python’s with statement and context managers.
The with statement in Python simplifies resource management by ensuring that setup and cleanup code runs automatically. It works with context managers, objects that define __enter__() and __exit__() methods to set up and tear down resources like file handles or database connections. Using with guarantees that resources are properly released even if exceptions occur. This leads to cleaner, safer code compared to manual try-finally blocks. You can also create custom context managers using the contextlib module or by defining the special methods yourself. This feature improves reliability in resource handling.
- How do you handle multithreading in Python despite the GIL?
Because of the GIL, Python threads cannot achieve true parallelism for CPU-bound tasks but are useful for I/O-bound operations like network requests or file I/O where threads wait for external resources. For CPU-intensive tasks, Python’s multiprocessing module creates separate processes, each with its own Python interpreter and memory space, bypassing the GIL. Another approach is using asynchronous programming with asyncio for concurrency. Some C extensions release the GIL during computation. Choosing the right concurrency model depends on your specific task requirements and system resources.
- What is a Python metaclass?
A metaclass in Python is a class of a class that defines how classes behave. Just as objects are instances of classes, classes themselves are instances of metaclasses. Metaclasses control class creation by customizing class attributes, methods, or inheritance during class definition. They are powerful but complex tools used mainly in frameworks or libraries to enforce design patterns or API contracts. You define a metaclass by inheriting from type and overriding special methods like __new__ or __init__. Understanding metaclasses requires a deep grasp of Python’s object model.
- Explain Python’s async and await keywords.
async and await are used to write asynchronous code that runs concurrently without traditional threads. Declaring a function with async def makes it a coroutine, which can pause execution at await expressions to let other coroutines run. This allows efficient handling of I/O-bound tasks like web requests or database queries without blocking the main thread. The event loop schedules and manages these coroutines. This asynchronous approach improves performance in applications requiring concurrency but minimal parallel CPU work. Using asyncio along with these keywords makes Python well-suited for modern async programming.
- How is exception chaining done in Python?
Exception chaining in Python allows you to associate a new exception with a previous one, preserving the original error context. This is done automatically when an exception occurs inside an except block or manually using the raise … from … syntax. By chaining exceptions, you provide better debugging information by showing both the root cause and the subsequent error. This feature improves error traceability in complex applications. When printing the traceback, Python displays the entire chain of exceptions, helping developers understand error propagation.
- What are Python’s comprehensions limitations?
While Python comprehensions are concise and efficient, they can become unreadable if overused or nested too deeply. Excessively complex comprehensions can hinder code clarity and maintainability. Also, comprehensions construct the entire output in memory, which may be inefficient for large datasets, unlike generators that yield one item at a time. Additionally, comprehensions are limited to single expressions and cannot contain statements like assignments or multiple complex statements. For more complicated transformations, using regular loops or functions may be preferable. Understanding when not to use comprehensions is as important as knowing how to use them.
- How do you manage Python memory leaks?
Although Python’s garbage collector manages most memory cleanup automatically, leaks can still occur, often due to lingering references such as circular references with objects that define __del__ or global variables holding large data. Using the gc module’s debugging tools helps identify unreachable objects. Developers must be careful when holding references in caches, closures, or long-lived data structures. Profiling tools like tracemalloc track memory allocation and leaks. Explicitly breaking circular references or using weak references can prevent leaks. Proactive management ensures applications run efficiently over time.
- What are Python’s built-in modules for threading and multiprocessing?
Python’s threading module provides higher-level threading interfaces for running concurrent threads, useful for I/O-bound tasks but limited by the GIL for CPU-bound operations. For true parallelism in CPU-bound tasks, Python’s multiprocessing module creates separate processes that run independently with their own memory space, circumventing the GIL. Both modules offer synchronization primitives like locks and queues. The concurrent.futures module provides a higher-level API for threading and multiprocessing with thread and process pools. Choosing the right module depends on task nature and concurrency requirements.
- What is the difference between map(), filter(), and reduce()?
map() applies a given function to all items in an iterable and returns a map object with the results. filter() applies a function that returns True or False to each item and returns only those items where the function is True. reduce(), from the functools module, applies a rolling computation to sequential pairs of items, reducing the iterable to a single cumulative value. While map and filter return iterators, reduce returns a single result. These functions support functional programming paradigms and can be replaced by comprehensions or loops but provide a concise syntax for specific tasks.
- How does Python handle method overriding?
Method overriding occurs when a subclass provides a new implementation for a method already defined in its superclass. When an overridden method is called on an instance of the subclass, the subclass’s version is executed, allowing customized behavior. This supports polymorphism and dynamic dispatch in object-oriented programming. Overriding allows extending or modifying the base class functionality. Python uses the method resolution order (MRO) to determine which method to call in inheritance hierarchies, especially with multiple inheritance. Calling the superclass method explicitly is done using super().
- What are Python’s special or magic methods?
Special methods, also called magic methods, are predefined methods in Python with double underscores (e.g., __init__, __str__, __add__). They allow objects to implement or override built-in behavior like initialization, string representation, arithmetic operations, and container behavior. By defining these methods, classes integrate seamlessly with Python’s syntax and built-in functions. For example, __len__ lets objects work with len(), and __getitem__ enables indexing. They are crucial for operator overloading and customizing object behavior in a Pythonic way.
- Explain Python’s slicing syntax.
Slicing extracts a subsequence from sequences like lists, tuples, or strings using the syntax sequence[start:stop:step]. The start index is inclusive, and the stop index is exclusive. The step defines the stride between elements, allowing forward or backward traversal if negative. Omitting indices defaults to start at 0 and stop at the end. Slicing creates a shallow copy of the sequence segment without modifying the original. It’s a powerful, concise way to manipulate and access data subsets efficiently.
- How does Python support multiple inheritance?
Python supports multiple inheritance, where a class can inherit from more than one parent class. This enables combining functionalities from multiple sources. Python resolves method calls using the Method Resolution Order (MRO), a linearization of classes ensuring a consistent order for searching methods. The super() function respects MRO, allowing cooperative multiple inheritance. While multiple inheritance offers flexibility, it can introduce complexity such as the diamond problem, which Python’s MRO handles elegantly. Careful design avoids ambiguity and maintains code clarity.
- What is the difference between a module and a package in Python?
A module is a single Python file containing definitions and statements, which can be imported and reused. A package is a collection of modules organized in directories with an __init__.py file (in Python versions before 3.3) to mark the directory as a package. Packages enable hierarchical structuring of modules, supporting scalable and organized codebases. You can import modules from packages using dot notation. This structure promotes modularity and reuse in larger Python applications.
- What is the purpose of the __init__.py file?
The __init__.py file marks a directory as a Python package, allowing it to be imported as a module. Before Python 3.3, it was mandatory for directories to contain this file to be recognized as packages. It can be empty or execute package initialization code, such as setting up namespaces or importing submodules. This file helps organize code and control what gets exposed when importing the package. In modern Python, implicit namespace packages reduce the strict need for this file but it remains widely used for compatibility and clarity.
- How does Python’s zip() function work?
The zip() function takes multiple iterables and aggregates elements from each into tuples, creating an iterator of paired items. It stops when the shortest input iterable is exhausted. This function is useful for parallel iteration over multiple sequences. For example, zip([1,2], [‘a’,’b’]) yields (1, ‘a’) and (2, ‘b’). Using * with zip() can unzip sequences. It simplifies data alignment and transformation tasks in Python programs.
- What is the difference between pass, continue, and break?
pass is a no-operation statement used as a placeholder where syntax requires a statement but no action is needed. continue skips the current iteration of a loop and proceeds to the next iteration. break immediately terminates the loop, exiting it altogether. These control flow statements manage how loops execute and are essential for fine-tuning loop behavior depending on conditions. Correct use ensures clearer and more efficient looping logic.
- How do you implement a singleton pattern in Python?
The singleton pattern ensures a class has only one instance and provides a global access point to it. In Python, it can be implemented by overriding the __new__ method to check if an instance already exists and returning it. Alternatively, decorators or metaclasses can enforce the singleton behavior. This pattern is used to manage shared resources or configurations in applications. Python’s dynamic nature allows several flexible ways to implement singletons, but it’s important to use it judiciously to avoid global state complications.
- What is the Global Interpreter Lock (GIL) in Python, and how does it affect threading?
The Global Interpreter Lock, or GIL, is a mutex that protects access to Python objects, preventing multiple native threads from executing Python bytecodes simultaneously. This means that even in multi-threaded programs, only one thread executes Python code at a time. While it simplifies memory management and prevents race conditions in CPython, it limits true parallelism in CPU-bound tasks. However, I/O-bound multi-threading benefits from the GIL because threads can release it while waiting for I/O operations. To achieve real parallelism in CPU-bound tasks, multiprocessing or alternative Python interpreters are used.
- How do Python decorators work?
Decorators in Python are functions that modify the behavior of another function or method. They take a function as input, wrap it in another function with additional functionality, and return the wrapper. Using the @decorator_name syntax above a function applies the decorator. Decorators enable reusable code for cross-cutting concerns like logging, access control, or memoization without modifying the original function code. They can be stacked to combine multiple behaviors and can also decorate classes or methods. This pattern encourages clean, modular, and DRY code.
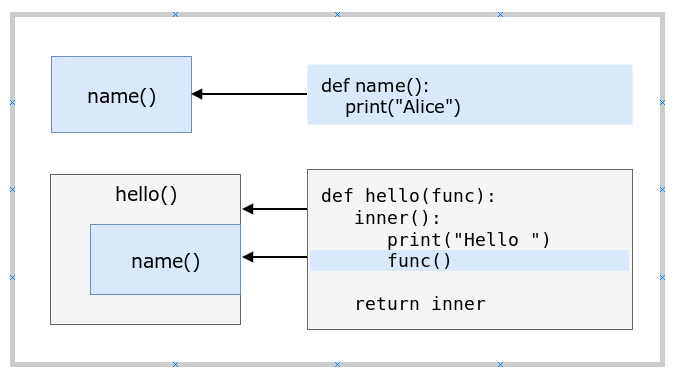
- What are generators in Python and how do they differ from regular functions?
Generators are special iterators created using functions with the yield keyword instead of return. Each call to yield produces a value and suspends the function’s state, allowing it to resume where it left off. This makes generators memory efficient as they produce items one at a time on demand rather than computing all at once. Unlike regular functions, which run to completion and return a value, generators provide lazy evaluation suitable for large or infinite data streams. They are commonly used in loops, pipelines, and asynchronous programming.
- Explain Python’s memory management and garbage collection.
Python manages memory automatically using reference counting, where each object tracks the number of references to it. When the count drops to zero, the memory is deallocated immediately. However, reference counting alone cannot detect cyclic references, so Python uses a cyclic garbage collector to identify and clean up reference cycles periodically. Developers can interact with this system via the gc module to tune or debug memory. This hybrid approach balances prompt deallocation with handling complex object graphs, reducing memory leaks and optimizing performance.
- What is the difference between @property and traditional getter/setter methods?
The @property decorator allows you to define methods that can be accessed like attributes, enabling controlled attribute access without changing the external interface. It improves code readability by avoiding explicit getter and setter method calls while still supporting validation or computation during access or assignment. Traditional getter/setter methods require explicit calls, which can clutter the code. Properties provide a Pythonic way to encapsulate data while keeping interfaces simple and intuitive, often used in object-oriented design.
- How can you handle exceptions in Python?
Exceptions in Python are handled using try-except blocks, where code that may raise an error is placed inside the try block, and handling code goes in the except block. You can catch specific exceptions to manage different error types appropriately and use multiple except clauses. The else block runs if no exceptions occur, and the finally block runs regardless of errors for cleanup tasks. Raising exceptions manually is done with the raise keyword. Proper exception handling ensures robustness and graceful failure in programs.
- What is monkey patching in Python?
Monkey patching refers to dynamic modifications of classes or modules at runtime, allowing you to change or extend behavior without modifying the original source code. This technique is useful for testing, fixing bugs, or adding features in third-party libraries. However, monkey patching can lead to maintenance challenges and unexpected side effects if overused or done carelessly. It leverages Python’s dynamic and flexible nature but requires caution and good documentation to avoid confusion.
- How do Python’s args and kwargs work in function definitions?
In Python, *args and **kwargs allow functions to accept an arbitrary number of positional and keyword arguments, respectively. *args collects extra positional arguments into a tuple, while **kwargs collects extra keyword arguments into a dictionary. This makes functions flexible and able to handle varying input parameters without explicitly defining all of them. These are commonly used in decorators, wrappers, and API functions. They help write generic and reusable code by accommodating various calling conventions.
- What are Python’s itertools and why are they useful?
The itertools module provides a collection of fast, memory-efficient tools for working with iterators. It includes functions for infinite sequences, combinatorics, filtering, grouping, and more. Using itertools avoids writing complex iterator logic manually, enabling concise and readable code for data processing tasks. They are especially useful in scenarios requiring efficient looping, permutations, or Cartesian products without loading entire datasets into memory. itertools is a fundamental library for advanced iteration patterns in Python.
- What are Python’s namedtuples?
namedtuple is a factory function in the collections module that creates tuple subclasses with named fields. Unlike regular tuples accessed by index, namedtuples allow you to access elements using attribute names, enhancing code readability. They are immutable and lightweight, combining the benefits of tuples with more expressive syntax. This structure is ideal for simple classes or data records where immutability and memory efficiency are priorities. They also support unpacking and can be used wherever regular tuples are used.
- What is the difference between shallow copy and deep copy in Python?
A shallow copy creates a new compound object but inserts references to the same objects found in the original, meaning changes to nested objects reflect in both copies. Deep copy, on the other hand, recursively copies all objects, creating fully independent objects including nested ones. Python’s copy module provides copy() for shallow and deepcopy() for deep copying. Shallow copies are faster but can cause side effects if mutable nested objects are modified, so deep copies are safer when complete independence is needed.
- How does Python handle memory allocation for objects?
Python uses a private heap space to manage memory for objects and data structures. The Python memory manager handles this heap, allocating and deallocating memory as needed. Objects like integers and strings are allocated in this heap, and small integers are cached for efficiency. Python’s built-in garbage collector and reference counting free unused memory automatically. Developers generally don’t manage memory directly, but understanding this system is crucial for optimizing performance and avoiding memory leaks.
- What is the difference between is and == operators?
The is operator checks if two variables point to the exact same object in memory (identity), whereas == checks if the values of the objects are equal (equality). For example, two lists with the same content are equal but not the same object. Using is for equality checks can lead to incorrect results, so it is mainly used for comparing singletons like None. Understanding this distinction prevents logical errors and improves code correctness.
- Explain how Python’s list comprehension works internally.
List comprehensions provide a concise way to create lists by iterating over iterables and optionally filtering elements. Internally, Python implements list comprehensions using a separate function frame to evaluate the expression for each iteration. They are faster than equivalent for loops because they are optimized in C at the interpreter level. List comprehensions build the list in memory immediately, so for very large datasets, generator expressions are preferred to save memory. Their readability and performance make them a common Python idiom.

- What is the difference between mutable and immutable objects in Python?
Mutable objects, like lists and dictionaries, can be changed after creation by modifying their contents. Immutable objects, such as strings, tuples, and integers, cannot be altered once created; any change produces a new object. This distinction affects how Python handles assignment and function arguments, impacting program behavior and performance. Immutable objects are hashable and can be used as dictionary keys, while mutable ones cannot. Knowing this difference is fundamental to writing efficient and bug-free Python code.
- How does the enumerate() function work in Python?
The enumerate() function adds a counter to an iterable and returns it as an enumerate object of tuples containing the index and the item. This is useful in loops where you need both the element and its position without manually managing a counter variable. It accepts an optional start argument to specify the starting index. Using enumerate() improves code clarity and reduces errors compared to manual index tracking.
- What is the difference between del and remove() in Python?
The del statement deletes an item at a specific index or slice from a list or removes a variable reference entirely. remove() is a list method that deletes the first occurrence of a specified value. del can work on slices and variables, whereas remove() works only on list elements by value. Using del on a variable removes the reference, possibly triggering garbage collection, while remove() modifies list contents. Understanding these differences helps manipulate data structures correctly.
- Explain Python’s staticmethod and classmethod.
A staticmethod is a method that belongs to a class but does not access the instance or class (self or cls). It behaves like a regular function but is called on the class. A classmethod, however, receives the class itself as the first argument (cls) and can modify class state. Both are used for organizing code logically within classes without requiring object instantiation. classmethods are useful for factory methods, while staticmethods are utility functions related to the class.
- What is the purpose of the with statement in file handling?
Using the with statement when working with files ensures that the file is properly opened and automatically closed after the block of code is executed, even if exceptions occur. This prevents resource leaks and makes the code cleaner compared to manually opening and closing files with open() and close(). The with statement uses context managers to manage resource setup and teardown, providing safe and efficient file handling.
- How can you optimize Python code for better performance?
Optimizing Python code involves profiling to identify bottlenecks, using efficient data structures, minimizing global variable access, and avoiding unnecessary computations. Techniques include using built-in functions and libraries, list comprehensions instead of loops, caching results with memoization, and employing concurrency or parallelism where appropriate. Using tools like cProfile, timeit, and external libraries such as NumPy can improve performance. Writing clear, maintainable code alongside optimization ensures sustainable improvements.
- What are Python’s data classes and how do they help?
Data classes, introduced in Python 3.7 via the dataclasses module, provide a decorator and functions for automatically adding special methods like __init__(), __repr__(), and __eq__() to classes. This reduces boilerplate code when creating classes primarily used to store data. By simply annotating attributes with types, data classes simplify object creation and improve readability. They also support default values, immutability (with frozen=True), and can be customized further, making data management cleaner and less error-prone.
- Explain how Python’s async and await keywords work.
async and await enable asynchronous programming in Python, allowing functions to run concurrently without blocking the main thread. Declaring a function with async def makes it a coroutine that returns a coroutine object. Using await inside such functions pauses execution until the awaited coroutine completes, allowing other tasks to run in the meantime. This is especially useful for I/O-bound and high-level structured network code, improving performance and responsiveness. It requires an event loop, typically managed by libraries like asyncio.
- What is the difference between copy.copy() and copy.deepcopy()?
copy.copy() performs a shallow copy, creating a new object but copying references to nested objects, so changes to mutable nested items affect both copies. copy.deepcopy() performs a deep copy by recursively copying all nested objects, resulting in fully independent duplicates. The deep copy is more resource-intensive but necessary when a true independent clone is required. Understanding when to use each prevents bugs related to shared mutable state and unexpected side effects.
- What are Python’s comprehensions and why are they useful?
Python supports list, set, and dictionary comprehensions which provide a concise syntax for constructing collections by iterating over iterables and optionally applying conditions. Comprehensions improve readability, reduce code length, and often enhance performance compared to traditional loops. For example, list comprehensions build new lists, set comprehensions produce unique element sets, and dictionary comprehensions create key-value mappings efficiently. They are a Pythonic way to write clear and expressive code.
- How do you manage dependencies in Python projects?
Dependency management involves specifying, installing, and updating external packages required by a project. This is commonly done using pip for package installation and requirements.txt files to list dependencies with specific versions. Virtual environments (venv, virtualenv) isolate project dependencies to avoid conflicts. More advanced tools like poetry or pipenv provide enhanced dependency resolution, version locking, and environment management. Proper dependency management ensures reproducible builds and avoids “dependency hell.”
- What is a Python iterator and how does it differ from an iterable?
An iterable is any Python object capable of returning its members one at a time, such as lists, tuples, or strings. It implements the __iter__() method returning an iterator. An iterator is an object with a __next__() method that returns the next item and raises StopIteration when exhausted. All iterators are iterables, but not all iterables are iterators. Understanding this distinction is crucial for designing efficient loops and custom iterable objects.
- Explain Python’s slice notation and negative indices.
Python’s slice notation sequence[start:stop:step] extracts a subsequence, where start is inclusive and stop is exclusive. The step parameter defines the stride and can be negative to reverse the sequence. Negative indices count from the end (-1 is last element), enabling flexible and readable slicing. Omitting parameters defaults to the start or end of the sequence. This notation is powerful for extracting, reversing, or skipping elements in sequences succinctly.
- What is the difference between a lambda function and a regular function?
A lambda function is an anonymous, inline function defined with the lambda keyword, typically limited to a single expression that returns a value. Regular functions use def and can contain multiple statements and complex logic. Lambdas are often used for short, throwaway functions in places like sorting, filtering, or callbacks, offering concise syntax. However, for readability and reuse, regular functions are preferred for more complex behavior.
- How do Python’s exception hierarchy and custom exceptions work?
Python’s built-in exceptions are organized in a hierarchy under the base class BaseException, with Exception as the main subclass for user-defined exceptions. You can create custom exceptions by subclassing Exception, allowing more specific error signaling. This hierarchy allows catching broad or narrow exception types. Proper use of custom exceptions improves code clarity, error handling, and debugging by providing meaningful context for failures.
- How can you improve the startup time of a Python program?
To improve Python program startup time, minimize imports by lazy loading modules only when needed, avoid unnecessary heavy libraries at import time, and optimize import order. Using tools like pyinstaller to create executables or pypy for faster startups can help. Profiling with modules like importlib can identify slow imports. Reducing I/O and heavy initialization during startup also speeds up the launch. These techniques improve responsiveness, especially for CLI tools or scripts.
- What are metaclasses in Python and when would you use them?
Metaclasses in Python are classes of classes that define how classes behave. A class is an instance of a metaclass. They allow customization of class creation, enabling modification of class attributes or methods at the time the class is defined. Metaclasses are powerful for enforcing coding standards, automatically registering classes, or creating APIs. Although useful, they add complexity and are typically used in advanced frameworks or libraries where class behavior needs to be controlled globally.
- How does Python’s garbage collector handle circular references?
Python’s garbage collector primarily uses reference counting, but it cannot clean up objects involved in reference cycles where two or more objects reference each other, preventing their reference count from dropping to zero. To address this, Python includes a cyclic garbage collector that periodically detects and collects groups of objects involved in such cycles. It uses algorithms to identify unreachable cycles and frees their memory. Developers can interact with this process via the gc module for tuning or debugging memory issues.
- What is the difference between map(), filter(), and list comprehensions?
map() applies a function to all items in an iterable, returning a map object with the results. filter() applies a function to filter items based on a boolean condition, returning an iterator of elements where the function is True. List comprehensions achieve similar results in a more readable and often faster way by combining looping and conditional logic into concise syntax. While map() and filter() are functional programming tools, list comprehensions are preferred in idiomatic Python for clarity and expressiveness.
- Explain the concept of duck typing in Python.
Duck typing is a programming concept where the suitability of an object is determined by the presence of certain methods or behavior rather than the object’s type itself. The phrase “If it looks like a duck and quacks like a duck, it’s a duck” summarizes this. In Python, this means that an object’s ability to be used in a particular context depends on whether it implements the required interface, not its inheritance hierarchy. This supports flexible and dynamic code but requires careful design and testing.
- How do you implement a singleton pattern in Python?
The singleton pattern ensures that a class has only one instance and provides a global point of access to it. In Python, it can be implemented using module-level variables, decorators, metaclasses, or by overriding the __new__ method to control instance creation. Using metaclasses is a clean approach that centralizes instance control. While singletons solve certain design problems, overuse can lead to global state management issues and should be applied judiciously.
- How does Python handle method resolution order (MRO) in multiple inheritance?
Python uses the C3 linearization algorithm to determine the method resolution order in classes with multiple inheritance. MRO defines the sequence in which base classes are searched when invoking methods. This ensures consistent and predictable behavior by respecting the order of inheritance and avoiding ambiguity. You can inspect the MRO of a class using the __mro__ attribute or the mro() method. Understanding MRO is vital when working with complex inheritance hierarchies.
- What are context managers in Python and how do you create one?
Context managers manage resources like file streams or locks by defining setup and teardown actions using __enter__ and __exit__ methods. They are used with the with statement to ensure proper acquisition and release of resources, even in cases of exceptions. Custom context managers can be created by defining these methods in a class or by using the contextlib module’s contextmanager decorator with generator functions. They help write clean, safe, and maintainable resource management code.
- What is the difference between bytes and str in Python?
str represents Unicode text in Python, whereas bytes is a sequence of raw 8-bit values used for binary data. str objects are immutable sequences of Unicode code points, supporting text operations and encoding/decoding. bytes are immutable sequences of bytes used in network communication, file I/O, or binary protocols. Conversion between them requires encoding (str to bytes) or decoding (bytes to str) using a character encoding like UTF-8. Understanding this distinction is crucial for handling text and binary data correctly.
- Explain Python’s zip() function and how it can be used.
The zip() function takes multiple iterables and aggregates elements from each into tuples, producing an iterator of tuples. It stops when the shortest input iterable is exhausted. This function is useful for parallel iteration over multiple sequences, pairing related elements, or combining data. The result can be converted to lists or other collections. zip() is commonly used in loops, data processing, and unpacking scenarios, making code concise and readable.
- What are Python’s built-in data structures and their typical use cases?
Python provides several built-in data structures such as lists, tuples, dictionaries, sets, and frozensets. Lists are ordered, mutable collections ideal for sequential data. Tuples are immutable sequences used for fixed collections or keys in dictionaries. Dictionaries store key-value pairs with fast lookups, widely used for mappings. Sets are unordered collections of unique elements useful for membership testing and operations like union or intersection. Each data structure is optimized for specific scenarios, and selecting the appropriate one improves code clarity and performance.
- What is the Global Interpreter Lock (GIL) in Python and how does it affect threading?
The Global Interpreter Lock, or GIL, is a mutex that protects access to Python objects, preventing multiple native threads from executing Python bytecodes simultaneously. This means even in multi-threaded Python programs, only one thread executes Python code at a time, which limits CPU-bound parallelism. However, for I/O-bound tasks, threads can still be effective. The GIL simplifies memory management but requires alternative approaches like multiprocessing or using C extensions for true parallel CPU-bound processing.
- How can you handle exceptions and ensure cleanup code runs in Python?
In Python, exceptions are handled using try-except blocks to catch and manage errors. To ensure that cleanup code runs regardless of whether an exception occurs, the finally block is used after try and except. The finally block always executes, making it ideal for releasing resources like file handles or network connections. This structure helps maintain program stability and resource integrity even during errors.
- What is the difference between @staticmethod and @classmethod decorators in Python?
@staticmethod defines a method that does not receive an implicit first argument and behaves like a regular function scoped inside the class. It cannot access instance (self) or class (cls) data. @classmethod defines a method that receives the class itself as the first argument (cls) and can modify class state or call other class methods. Both help organize code logically within classes, but classmethod is used when behavior depends on the class context.
- How do Python generators improve memory efficiency?
Generators yield items one at a time instead of creating the entire list in memory. This lazy evaluation allows handling large datasets or infinite sequences efficiently without loading everything at once. Using the yield keyword in a function turns it into a generator, producing values on demand. This approach reduces memory consumption and can improve performance, especially in streaming or data pipeline scenarios.
- What are Python’s magic methods? Can you name a few?
Magic methods, also known as dunder (double underscore) methods, allow customization of built-in behavior for objects. Examples include __init__ for object initialization, __str__ for string representation, __add__ for operator overloading, and __iter__ to make an object iterable. Implementing these methods enables classes to interact seamlessly with Python’s syntax and functions, making objects more intuitive and powerful.
- Explain how you can achieve multiple inheritance in Python and any issues that might arise.
Python supports multiple inheritance, allowing a class to inherit from more than one parent class. This enables combining behaviors and attributes from multiple sources. However, it can lead to complexity such as the diamond problem, where multiple paths to a common ancestor exist. Python resolves this using the Method Resolution Order (MRO) based on C3 linearization to determine the order in which base classes are searched. Careful design is necessary to avoid conflicts and maintain clarity.
- What are Python decorators and how do they work?
Decorators are functions that modify the behavior of other functions or methods. They take a function as input, wrap or extend its behavior, and return a new function. Applied using the @decorator_name syntax above a function, decorators enable code reuse, logging, access control, or instrumentation without changing the original function’s code. They are powerful tools for separation of concerns and enhancing code modularity.
- How do you handle missing keys in a Python dictionary?
To handle missing keys gracefully, you can use the dict.get() method which returns None or a specified default value if the key is absent. Alternatively, the collections.defaultdict provides a dictionary with a default factory function that creates default values for missing keys automatically. Using these avoids KeyError exceptions and simplifies code when working with dynamic or incomplete data.
- What is the purpose of the __init__.py file in Python packages?
The __init__.py file marks a directory as a Python package, allowing the import of modules from that directory. It can be empty or execute package initialization code, set __all__ for controlling import behavior, or expose selected modules and classes. This file is essential for structuring code into reusable and maintainable modules, enabling namespace management and hierarchical organization.
- How does Python’s zip() function behave when given iterables of different lengths?
When zip() is called with multiple iterables of unequal length, it stops aggregating as soon as the shortest iterable is exhausted. This means that the resulting iterator contains tuples only up to the length of the shortest input. To handle all elements regardless of length, itertools.zip_longest() can be used, which fills missing values with a specified fill value. Understanding this prevents unexpected data loss during parallel iteration.
- What are Python’s args and kwargs, and how are they used?
In Python, *args and **kwargs allow functions to accept a variable number of positional and keyword arguments, respectively. *args collects extra positional arguments into a tuple, while **kwargs collects extra keyword arguments into a dictionary. They enable flexible function interfaces, letting developers write functions that handle diverse inputs without explicitly defining all parameters. This is particularly useful in decorators, wrappers, or APIs where argument lists vary.
- How do you optimize Python code for performance?
Optimizing Python code involves multiple strategies: using built-in functions and libraries that are implemented in C, minimizing global variable access, avoiding unnecessary loops, and using list comprehensions or generator expressions for memory efficiency. Profiling tools like cProfile identify bottlenecks. For CPU-intensive tasks, leveraging concurrency with multiprocessing or using third-party libraries like NumPy can improve speed. Writing clean, readable code with efficient algorithms is also fundamental.
- Explain Python’s with statement and its benefits.
The with statement simplifies exception handling by encapsulating common preparation and cleanup tasks in context managers. It ensures resources like files or locks are properly acquired and released automatically, even if errors occur. This avoids boilerplate try-finally blocks and reduces resource leaks. The with syntax improves code readability and reliability, especially when managing external resources or complex setups.
- What is monkey patching in Python?
Monkey patching refers to the dynamic modification or extension of modules or classes at runtime without altering the original source code. This allows fixing bugs, changing behavior, or adding features temporarily during execution. While powerful, monkey patching can make code harder to understand and maintain, so it should be used judiciously and mainly in testing or plugin scenarios.
- How do you use Python’s logging module effectively?
The logging module provides a flexible framework for emitting log messages from Python programs. It supports different severity levels (DEBUG, INFO, WARNING, ERROR, CRITICAL), multiple output destinations (console, files, network), and configurable formats. Effective use involves configuring loggers, handlers, and formatters to capture important runtime information for debugging and monitoring without cluttering the output. Proper logging improves maintainability and troubleshooting.
- What is a Python coroutine and how is it different from a generator?
A coroutine is a special type of generator designed for asynchronous programming, capable of pausing and resuming execution at await expressions. While both use yield internally, coroutines use async def syntax and cooperate with an event loop for concurrency. Generators produce data lazily, whereas coroutines consume and produce data asynchronously, allowing efficient handling of I/O-bound tasks.
- How do you implement method overloading in Python?
Python does not support traditional method overloading by signature. Instead, method overloading is typically achieved by default arguments, variable-length argument lists (*args, **kwargs), or manually checking argument types and counts within a method. Libraries like functools.singledispatch enable function overloading based on argument types, providing a more structured approach. This flexibility matches Python’s dynamic nature.
- What is the difference between shallow copy and deep copy in Python?
A shallow copy creates a new object but inserts references to the original elements, meaning nested mutable objects are shared between the copy and the original. Changes to nested objects affect both. A deep copy recursively duplicates all nested objects, resulting in a fully independent clone. Python’s copy module provides copy.copy() for shallow and copy.deepcopy() for deep copying. Knowing when to use each prevents subtle bugs in data manipulation.
- How can you handle circular imports in Python?
Circular imports occur when two modules import each other, causing import errors. Solutions include restructuring code to reduce interdependencies, using local imports inside functions or methods to delay import time, or consolidating related functions into a single module. Import hooks or dynamic import techniques can also help, but careful design and modularization are the best ways to avoid circular import problems.
- What is Python’s enumerate() function and when would you use it?
The enumerate() function adds a counter to an iterable and returns it as an enumerate object of index-element pairs. It is commonly used in loops when you need both the item and its position without manually managing a counter variable. This improves code readability and reduces errors, especially when iterating over sequences where the index is required alongside the value.
- What is the difference between mutable and immutable objects in Python?
In Python, mutable objects can be changed after creation, while immutable objects cannot. Examples of mutable objects include lists, dictionaries, and sets, where you can add, remove, or modify elements. Immutable objects include strings, tuples, and integers, whose values remain constant after creation. Understanding this distinction is important for predicting how objects behave when passed as function arguments or assigned to new variables, affecting program logic and performance.
- How do you manage memory in Python?
Python manages memory automatically through reference counting and a cyclic garbage collector that cleans up unused objects, especially those involved in reference cycles. Programmers do not usually need to manually allocate or free memory, but understanding how Python’s memory model works helps optimize resource usage. Tools like the gc module assist in tuning garbage collection, and techniques such as using generators reduce memory footprint in large data processing.
- Explain the use of the super() function in Python.
The super() function returns a proxy object that delegates method calls to a parent or sibling class, enabling you to call methods from a superclass in a subclass. It’s especially useful in multiple inheritance scenarios to ensure proper initialization and method chaining. Using super() promotes maintainable and scalable code by avoiding explicit base class names, supporting cooperative inheritance patterns.
- What is the difference between is and == operators in Python?
The is operator checks for object identity, i.e., whether two references point to the exact same object in memory. The == operator checks for value equality, meaning whether two objects have equivalent data. For immutable types like integers and strings, is and == can sometimes behave similarly due to interning, but generally, is is used for identity comparison, and == for equality of content.
- How do you implement a Python class property?
A property in Python is a managed attribute that allows you to add logic around getting, setting, or deleting an attribute using decorators like @property, @<property_name>.setter, and @<property_name>.deleter. This encapsulation helps maintain data integrity and hide implementation details while providing a simple attribute interface to users of the class. Properties improve object-oriented design by controlling access with getter/setter methods transparently.
- What are lambda functions and where are they used?
Lambda functions are anonymous, inline functions defined with the lambda keyword. They can take any number of arguments but only have one expression which is implicitly returned. Lambdas are commonly used in places where short, throwaway functions are needed, such as sorting keys, filtering data, or as callbacks in event-driven programming. Their concise syntax enhances code readability when used appropriately.
- Describe Python’s list slicing syntax and its use cases.
List slicing uses the syntax [start:stop:step] to extract a portion of a list or other sequence types. It returns a new list containing elements from the start index up to but not including the stop index, moving in steps defined by step. Slicing is useful for subsetting data, reversing sequences, or copying lists efficiently. It supports negative indices to count from the end, enabling flexible data manipulation.
- How does exception propagation work in Python?
When an exception occurs, Python looks for a matching except block in the current function. If none is found, the exception propagates up the call stack to the caller. This continues until an appropriate handler is found or the program terminates. This mechanism allows errors to be handled at different abstraction levels and supports writing robust programs by centralizing error handling.
- What is the difference between filter() and list comprehensions in Python?
Both filter() and list comprehensions are used to create filtered lists based on a condition. filter() takes a function and an iterable, returning an iterator yielding items where the function returns True. List comprehensions use a more readable syntax combining looping and conditional logic in a single expression. List comprehensions are generally preferred in Python for clarity and performance, while filter() is useful when you already have a function or prefer functional style.
- How can you improve Python code readability?
Improving readability involves following PEP 8 style guidelines, using meaningful variable and function names, writing modular and well-documented code, and avoiding complex one-liners. Proper indentation, consistent naming conventions, and use of comments and docstrings enhance maintainability. Writing clear logic flow, minimizing side effects, and preferring built-in functions also contribute to more understandable and professional codebases.
- What are metaclasses in Python and when would you use them?
Metaclasses are the “classes of classes” that define how classes behave. A metaclass controls the creation of classes, allowing you to modify or customize class instantiation and inheritance behavior. You use metaclasses when you want to enforce certain constraints, automatically register classes, or modify class attributes during creation. They are an advanced feature and useful for frameworks or APIs requiring dynamic class behavior.
- How does Python manage memory for small integers and strings?
Python uses an internal optimization technique called interning for small integers (usually from -5 to 256) and some strings. These objects are pre-allocated and reused to improve performance and memory efficiency. This means that small integers and interned strings with the same value point to the same memory location. This optimization affects identity comparisons (is) and reduces overhead in programs dealing with many identical literals.
- What is the difference between a module and a package in Python?
A module is a single Python file (.py) containing code definitions, functions, and classes. A package is a collection of modules organized in directories with an __init__.py file, which can contain initialization code for the package. Packages allow hierarchical structuring of the module namespace and promote modularity and reuse. Essentially, modules are building blocks, and packages are collections of those blocks.
- Explain how Python’s garbage collector works with reference cycles.
Python’s garbage collector uses reference counting as the primary memory management technique but struggles with reference cycles where objects reference each other, preventing their reference counts from reaching zero. To solve this, Python includes a cyclic garbage collector that periodically identifies and frees groups of objects involved in reference cycles. This collector runs in the background and helps avoid memory leaks, especially when objects have __del__ methods.
- What is the difference between map() and list comprehensions?
Both map() and list comprehensions apply a function to each item in an iterable. map() takes a function and an iterable, returning an iterator yielding the results. List comprehensions achieve the same in a more readable and Pythonic way with [func(x) for x in iterable]. List comprehensions offer greater flexibility by including conditional expressions and multiple loops, while map() is useful for applying existing functions directly.
- How can you make a Python class iterable?
To make a class iterable, you need to implement the __iter__() method that returns an iterator object, which must implement the __next__() method. The __iter__() method returns self if the object itself is the iterator. This allows using instances of the class in for loops or other constructs that consume iterables. This design pattern enables custom container classes to integrate seamlessly with Python’s iteration protocol.
- How is multithreading achieved in Python despite the GIL?
Despite the Global Interpreter Lock (GIL) restricting true parallel execution of Python bytecodes in threads, multithreading in Python is useful for I/O-bound operations like file or network I/O where threads spend much time waiting. Threads can switch during blocking I/O, improving responsiveness and throughput. For CPU-bound tasks, Python’s multiprocessing module or alternative implementations like Jython or IronPython are used to bypass the GIL.
- What are Python’s data descriptors and how do they work?
Data descriptors are objects that implement both __get__() and __set__() methods and control attribute access in classes. They are used in properties, methods, and other attribute management mechanisms to intercept getting and setting attribute values. Descriptors enable reusable, customizable attribute behavior like validation or computed properties. Understanding descriptors is key to advanced Python class design and metaprogramming.
- How can you prevent a Python script from running when imported?
To prevent code from running when a script is imported as a module, wrap the executable code inside an if __name__ == “__main__”: block. This condition checks whether the script is run directly or imported; the code inside the block runs only when executed as the main program. This practice enables scripts to provide reusable functions without side effects upon import.
- What is the use of __slots__ in Python classes?
The __slots__ declaration in a class defines a fixed set of attributes, preventing the creation of the usual dynamic __dict__ for instances. This can reduce memory consumption and improve attribute access speed for classes with many instances. However, it restricts the ability to add new attributes dynamically. Using __slots__ is a useful optimization technique in performance-critical applications.
- What are Python decorators and how do they work?
Python decorators are functions that modify the behavior of another function or method without changing its code. They take a function as input, add functionality, and return a new function. Decorators are widely used for logging, access control, memoization, and timing. They are applied using the @decorator_name syntax and work by wrapping the original function, allowing reusable and clean code enhancements.
- How do Python generators improve memory efficiency?
Generators produce items one at a time and only when requested, instead of creating and storing the entire sequence in memory. This lazy evaluation makes generators highly memory efficient for large datasets or infinite sequences. Using yield statements, generators pause and resume execution, enabling iteration without the overhead of list creation. This reduces memory consumption and improves performance for streaming data or pipelines.
- What are Python’s comprehensions and how do they differ from loops?
Comprehensions provide concise syntax for creating lists, sets, or dictionaries from iterables using a single expression. Unlike traditional loops, comprehensions combine looping and conditional filtering in one readable line, often resulting in faster and cleaner code. For example, a list comprehension [x*2 for x in range(5)] replaces a multi-line loop, improving maintainability without sacrificing clarity.
- How does Python handle method resolution order (MRO) in multiple inheritance?
Python uses the C3 linearization algorithm to determine the Method Resolution Order (MRO) when classes inherit from multiple parents. This order defines the sequence in which base classes are searched when calling a method. The MRO ensures a consistent, predictable lookup that respects inheritance hierarchies and avoids ambiguity. You can inspect MRO using the __mro__ attribute or mro() method on a class.
- What is the difference between staticmethod and classmethod?
A staticmethod is a method that does not receive an implicit first argument and behaves like a regular function inside a class namespace. It cannot access instance or class data. In contrast, a classmethod receives the class as the first argument (cls) and can modify class state or call other class methods. Both decorators organize code logically within classes but serve different purposes in accessing data.
- How do you handle exceptions in Python?
Exceptions in Python are handled using try-except blocks where the risky code is placed inside try, and exceptions are caught in except. You can specify exception types to catch specific errors and use else for code that runs if no exceptions occur. The finally block runs regardless of exceptions, useful for cleanup. Proper exception handling ensures programs run smoothly and errors are gracefully managed.
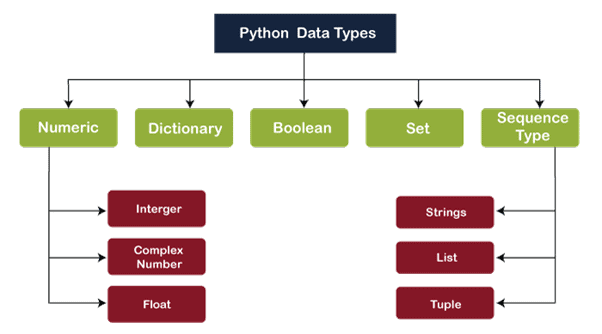
- What are Python’s built-in data types?
Python’s built-in data types include immutable types like integers, floats, strings, tuples, and booleans, and mutable types like lists, dictionaries, sets, and byte arrays. These types provide fundamental building blocks for data manipulation, supporting arithmetic, indexing, and various methods. Understanding these types and their properties is essential for effective Python programming.
- How do Python’s global and nonlocal keywords work?
The global keyword declares that a variable inside a function refers to a globally defined variable, allowing modification of the global variable. The nonlocal keyword applies to variables in the nearest enclosing (non-global) scope, letting nested functions modify outer function variables. These keywords help control variable scope and avoid issues related to variable shadowing or unintended local assignment.
- What is the difference between list and tuple in Python?
Lists are mutable sequences that allow modification after creation, such as adding or removing elements. Tuples are immutable sequences that cannot be changed once defined. Due to immutability, tuples are faster and can be used as dictionary keys or set elements, unlike lists. Choosing between them depends on whether the data should remain constant or be updated during program execution.
- Explain Python’s slicing with negative indices.
Python supports negative indices in slicing, which count backward from the end of a sequence, where -1 is the last element. For example, list[-3:-1] extracts elements starting from the third-last up to but not including the last. Negative indexing combined with slicing offers powerful and concise ways to access subsequences without calculating explicit positive indices, improving code expressiveness.
- What is the difference between a generator and an iterator in Python?
An iterator is an object that implements the iterator protocol with __iter__() and __next__() methods, allowing sequential access to elements. A generator is a special kind of iterator defined by a function using yield statements, which pauses function execution and produces values lazily. Generators simplify iterator creation, reduce memory usage, and are preferred for producing sequences on the fly.
- How can you create a virtual environment in Python, and why is it important?
A virtual environment isolates Python packages for different projects, preventing dependency conflicts. You can create one using python -m venv env_name, then activate it (source env_name/bin/activate on Unix or env_name\Scripts\activate on Windows). This ensures project-specific libraries do not interfere globally, making development more manageable and reproducible.
- What is the Global Interpreter Lock (GIL) in Python?
The GIL is a mutex in CPython that prevents multiple native threads from executing Python bytecodes simultaneously. It simplifies memory management but restricts true parallelism in CPU-bound multi-threaded programs. While it limits concurrency, it allows efficient I/O-bound threading and is bypassed using multiprocessing or alternative interpreters.
- Explain the difference between deep copy and shallow copy.
A shallow copy creates a new object but copies references of nested objects, so changes to nested mutable objects reflect in both copies. A deep copy recursively duplicates all nested objects, creating fully independent copies. Python’s copy module provides copy.copy() for shallow and copy.deepcopy() for deep copying. Choosing the right copy type prevents unintended side effects.
- What is the purpose of Python’s zip() function?
The zip() function aggregates elements from multiple iterables into tuples, pairing corresponding items. It stops at the shortest input iterable length. This is useful for parallel iteration over sequences, combining data sources, or transposing matrices. It simplifies code by replacing manual index-based iteration.
- How does Python’s try-except-else-finally structure work?
In this structure, the try block contains code that might raise exceptions. The except block handles specific exceptions. The optional else block runs if no exceptions occur, and finally runs always regardless of exceptions, useful for cleanup tasks. This control flow provides robust and clear error handling.
- What is list comprehension, and how does it differ from map and filter?
List comprehension creates new lists using an expressive syntax that combines iteration and conditionals in one line. map() applies a function to each item, and filter() selects items based on a predicate. Comprehensions are often more readable and flexible, supporting complex expressions inline.
- How do you manage package dependencies in Python projects?
Dependencies are managed using tools like pip for installation and requirements.txt files to specify package versions. Virtual environments isolate project dependencies. Advanced tools like pipenv and poetry automate dependency resolution, lock versions, and simplify environment management, improving reproducibility and collaboration.
- What are Python’s built-in data structures?
Python’s built-in data structures include lists, tuples, sets, dictionaries, and strings. Lists are ordered, mutable sequences; tuples are ordered, immutable sequences; sets are unordered collections of unique elements; dictionaries store key-value pairs; and strings represent sequences of characters. Each serves different purposes in organizing data efficiently.
- What is a lambda function and where is it typically used?
A lambda function is a small anonymous function defined with the lambda keyword, taking any number of arguments but containing only one expression. They are often used as short callbacks, in sorting, filtering, or functional programming constructs where defining a full function is unnecessary. Lambdas enhance concise and readable code in such cases.
- How does Python’s with statement work and why is it used?
The with statement simplifies exception handling by encapsulating common preparation and cleanup tasks in context managers. It ensures that resources like files or network connections are properly acquired and released, even if errors occur. Internally, it calls the context manager’s __enter__ and __exit__ methods, making code cleaner, safer, and more readable by abstracting boilerplate resource management.
- What is the difference between mutable and immutable types?
Mutable types like lists, dictionaries, and sets can be changed after creation, allowing modifications such as adding, updating, or removing elements. Immutable types, including strings, tuples, and integers, cannot be altered once created; operations on them result in new objects. This distinction affects program behavior, especially in function arguments and caching, and is crucial for understanding data handling in Python.
- How can you improve the performance of a Python program?
Performance improvements can come from profiling code to find bottlenecks, using efficient algorithms and data structures, leveraging built-in functions, and minimizing unnecessary computations. Tools like cProfile help identify slow areas. Using generators to save memory, employing multithreading or multiprocessing for parallel tasks, and integrating C extensions or libraries like NumPy can drastically enhance speed and efficiency.
- What are Python’s comprehensions and generator expressions?
Comprehensions provide concise syntax for creating sequences like lists, sets, or dictionaries by iterating and filtering elements inline. Generator expressions look similar but use parentheses and generate items lazily, producing one item at a time without storing the entire sequence in memory. Generators improve memory efficiency, especially for large or infinite datasets.
- What is monkey patching in Python?
Monkey patching refers to dynamically modifying or extending a module or class at runtime without altering its original source code. It’s often used for quick fixes, testing, or extending third-party libraries. While powerful, it can lead to maintenance challenges and unexpected side effects, so it should be used judiciously with clear documentation.
- How are Python’s dictionaries implemented?
Python dictionaries use a hash table to provide average O(1) time complexity for lookups, insertions, and deletions. Keys are hashed to determine their position in an internal array. Collisions are resolved by probing, and the table resizes dynamically to maintain performance. Recent Python versions maintain insertion order, combining efficiency with predictability.
- What is the difference between pass, continue, and break statements?
pass is a null statement that does nothing and is used as a placeholder. continue skips the current iteration of a loop and moves to the next one. break exits the loop entirely, stopping further iterations. These control flow statements help manage loops’ behavior effectively based on conditions.
- How do you handle missing keys in a Python dictionary?
Missing keys can be handled using the get() method, which returns None or a default value if the key isn’t present, preventing KeyErrors. Alternatively, defaultdict from the collections module provides a default value automatically when accessing nonexistent keys. Using try-except blocks to catch KeyErrors is another method but generally less elegant.
- What is a Python iterator protocol?
The iterator protocol requires an object to implement the __iter__() method, returning an iterator object that defines a __next__() method. The __next__() method returns the next item or raises StopIteration when no more items are available. This protocol enables objects to be iterable, working with loops and functions like next().
- How does Python handle variable scope?
Python variables follow the LEGB rule: Local, Enclosing, Global, Built-in scopes. When resolving variable names, Python looks first in the local function scope, then any enclosing functions, then the global module scope, and finally the built-in namespace. Understanding
- What are Python’s magic methods and why are they important?
Magic methods, also called dunder methods (double underscores), are special methods like __init__, __str__, and __add__ that Python calls implicitly to implement operator overloading and customize object behavior. They allow developers to define how objects behave with built-in functions and operators, enabling custom classes to integrate naturally with Python syntax and idioms, making code more intuitive and expressive.
- How does Python’s enumerate() function work?
The enumerate() function adds a counter to an iterable, returning an iterator of tuples containing the index and the corresponding element. This is useful when you need both the item and its position in a loop, improving code readability by avoiding manual counter management. It supports a start parameter to specify the initial index, which defaults to zero.
- What is the difference between is and == in Python?
The is operator checks for object identity, meaning it returns True if two variables point to the same object in memory. The == operator checks for value equality, meaning it returns True if the objects have the same value, even if they are different instances. Understanding this distinction is important to avoid logical errors, especially when comparing mutable objects.
- How can you handle command-line arguments in Python?
Python provides the sys.argv list for basic command-line argument handling, containing the script name and subsequent arguments as strings. For more sophisticated parsing, the argparse module allows defining expected arguments, types, default values, and help messages, making scripts user-friendly and robust for command-line usage in real-world applications.
- What is a context manager in Python?
A context manager is an object that defines runtime context to be established and cleaned up, usually implemented with __enter__() and __exit__() methods. It is used with the with statement to manage resources like file streams or database connections, ensuring that resources are properly acquired and released, which helps prevent leaks and improves code clarity.
- How do you create a Python package?
Creating a Python package involves organizing modules into a directory containing an __init__.py file. This file can be empty or execute initialization code, marking the directory as a package. Packages enable modular, reusable code structures and can be distributed via package managers like pip, facilitating scalable project organization.
- Explain Python’s slicing syntax.
Python slicing extracts parts of sequences using [start:stop:step] syntax, where start is the beginning index (inclusive), stop is the ending index (exclusive), and step indicates the stride between elements. Omitting parameters uses defaults: start at 0, stop at sequence end, and step of 1. Slicing is versatile, supporting negative indices and steps to traverse sequences backwards or selectively.
- What is the purpose of the yield keyword?
The yield keyword turns a function into a generator, pausing execution and returning a value to the caller while maintaining its internal state for subsequent resumes. This enables lazy evaluation and efficient handling of large or infinite sequences without loading all data into memory, improving performance and responsiveness in data processing.
- How do you implement encapsulation in Python?
Encapsulation is implemented by prefixing instance variables or methods with underscores to indicate they are intended as private (_single_underscore or __double_underscore). Python does not enforce strict access control but relies on naming conventions to signal intended usage. Encapsulation helps protect internal state and encourages modular, maintainable code design.
- What are Python’s built-in functions for type conversion?
Python provides built-in functions like int(), float(), str(), list(), tuple(), set(), and dict() to convert data between types. These functions are useful for ensuring data is in the correct format for operations or interfacing with APIs. Proper type conversion helps avoid errors and enhances data processing flexibility.
- What are Python’s iterables and iterators, and how do they differ?
In Python, an iterable is any object capable of returning its elements one at a time, allowing it to be looped over, such as lists, tuples, and strings. An iterator is an object that actually performs the iteration by implementing the __next__() method and returning elements one by one. Iterables produce iterators when passed to the iter() function. The main difference is that iterables provide a way to get iterators, which do the actual traversal.
- How can you optimize Python code for large datasets?
Optimizing Python code for large datasets involves multiple strategies: using generators to process data lazily instead of loading everything into memory, leveraging efficient data structures like NumPy arrays, and minimizing expensive operations inside loops. Profiling tools can help identify bottlenecks. Also, using built-in functions and libraries optimized in C, or parallelizing workloads via multiprocessing, improves speed and memory efficiency.
- What is the difference between args and kwargs in Python functions?
*args allows a function to accept an arbitrary number of positional arguments as a tuple, while **kwargs accepts arbitrary keyword arguments as a dictionary. This flexibility enables defining functions that can handle variable input sizes and named parameters, making them more general and adaptable. Both can be combined in function signatures to accept a mix of arguments.
- How does Python manage memory?
Python manages memory automatically through a private heap space, where all objects and data structures are stored. The Python memory manager handles allocation and deallocation, while a built-in garbage collector tracks reference counts and frees objects when no longer used. Cyclic references are cleaned up by the garbage collector’s cyclic detection, preventing memory leaks.
- What is the difference between a module and a package in Python?
A module is a single Python file containing definitions and statements, while a package is a directory that contains multiple modules along with an __init__.py file, allowing hierarchical organization of modules. Packages help organize code into namespaces and enable modular and reusable codebases, making large projects easier to manage.
- How can you handle file operations in Python?
File operations in Python are managed through built-in functions like open(), which opens files in various modes such as read, write, or append. You can read or write file content using methods like read(), readline(), write(), and writelines(). Using the with statement ensures files are properly closed after operations, avoiding resource leaks.
- What is list slicing and how is it useful?
List slicing extracts a portion of a list using the syntax [start:stop:step]. It is useful for creating sublists, reversing lists with a negative step, and copying lists efficiently. Slicing is versatile, allowing selection of elements at regular intervals and working with negative indices to access elements from the end, making sequence manipulation concise.
- Explain Python’s map() function and its typical use cases.
The map() function applies a given function to all items in an iterable, returning a map object which can be converted to other sequences. It’s typically used for transforming data efficiently without explicit loops. Combined with lambda functions, map() supports functional programming paradigms and can improve readability when applying simple transformations.
- What are Python’s set data structures, and what are their advantages?
A set is an unordered collection of unique elements in Python, implemented using hash tables. Sets support fast membership testing, union, intersection, and difference operations. They are ideal when uniqueness and efficient lookup are important, such as removing duplicates from lists or performing mathematical set operations in algorithms.
- How can you debug Python code effectively?
Effective debugging in Python can be done using print statements for simple cases or using the built-in pdb module for interactive debugging. IDEs provide debugging tools with breakpoints, watches, and step execution. Logging modules help track program flow in production. Profiling tools identify performance issues, and careful exception handling ensures robust error diagnosis.
- What is the purpose of the __init__.py file in a Python package?
The __init__.py file signals to Python that the directory should be treated as a package. It can be empty or execute initialization code for the package, such as importing submodules or setting package-level variables. This file enables hierarchical module organization and allows importing modules using the package namespace.
- How do you handle exceptions in Python with custom exception classes?
Custom exceptions are created by subclassing Python’s built-in Exception class. This allows developers to define specific error types relevant to their application, improving error clarity and handling. Raising and catching these exceptions makes code more readable and manageable, especially in complex applications where generic exceptions are insufficient.
- What are decorators in Python and how do they work?
Decorators are functions that modify the behavior of other functions or methods without changing their code. They take a function as input and return a new function with enhanced or altered functionality. Used with the @decorator_name syntax, they are commonly applied for logging, access control, or memoization, promoting code reuse and separation of concerns.
- What is the difference between @staticmethod and @classmethod?
A @staticmethod is a method that does not receive an implicit first argument and behaves like a regular function inside a class namespace. A @classmethod receives the class itself (cls) as the first argument, allowing it to modify class state or instantiate new instances. Both help organize code logically within classes but serve different use cases.
- Explain Python’s garbage collection mechanism.
Python primarily uses reference counting to track object usage, deallocating objects when their reference count drops to zero. To handle cyclic references that reference counting alone can’t clear, Python’s garbage collector periodically detects and frees these cycles. This two-pronged approach helps manage memory efficiently and prevents leaks.
- What are Python’s data descriptors and how do they differ from non-data descriptors?
Data descriptors implement both __get__() and __set__() methods and manage attribute access and modification. Non-data descriptors only implement __get__(). The key difference is that data descriptors take precedence over instance dictionaries when attributes are accessed, allowing stricter control, useful in properties and attribute management.
- How do Python’s list and tuple differ in terms of performance?
Tuples are generally faster than lists for iteration and creation due to their immutability, which allows certain optimizations. Since tuples are immutable, Python can make memory and speed optimizations that are not possible with mutable lists. This makes tuples preferable for fixed collections of data where performance is critical.
- What is the global keyword and when should you use it?
The global keyword allows functions to modify variables defined at the module (global) scope. Without it, assignments create new local variables. Use of global is often discouraged except when necessary because it can make code harder to understand and maintain, so encapsulating state in objects or passing parameters is usually better.
- How can you achieve multithreading in Python, and what are its limitations?
Multithreading in Python is implemented via the threading module, enabling concurrent execution of threads. However, due to the Global Interpreter Lock (GIL), only one thread executes Python bytecode at a time, limiting CPU-bound parallelism. It is effective for I/O-bound tasks like network or file operations but not for CPU-intensive computations.
- What is a metaclass in Python?
A metaclass is a class of a class, defining how classes themselves behave. It controls class creation, allowing customization of class attributes and methods during class definition. Metaclasses are powerful but complex, primarily used in advanced frameworks or libraries to enforce constraints or modify class behavior dynamically.
- What are Python’s generators and how do they differ from normal functions?
Generators are special functions that return an iterator and yield values one at a time, suspending and resuming their state between each yield. Unlike normal functions that return a single value and terminate, generators produce a sequence of values lazily, which makes them memory efficient for large data streams or infinite sequences.
- How do you manage package dependencies in Python projects?
Package dependencies are commonly managed using tools like pip and environment files such as requirements.txt which list all required packages with specific versions. Virtual environments (using venv or conda) isolate project dependencies, preventing conflicts between projects and ensuring reproducible builds.
- Explain the difference between deep copy and shallow copy in Python.
A shallow copy creates a new compound object but inserts references to the objects found in the original, so changes to nested objects affect both copies. A deep copy creates a fully independent clone, recursively copying all nested objects, ensuring changes to the copy do not affect the original.
- How do Python’s list comprehensions improve code readability and performance?
List comprehensions provide a concise and expressive way to create lists by embedding loops and conditions inside square brackets. They often run faster than equivalent for-loops because they are optimized internally. Their compact syntax improves readability by reducing boilerplate code.
- What is the difference between raise and assert statements?
raise is used to explicitly throw an exception when an error condition occurs, allowing for custom error handling. assert is mainly used during debugging to check assumptions, raising an AssertionError if the condition is false, and can be disabled in optimized runs. Thus, assert is not a substitute for error handling.
- How can you improve the startup time of a Python application?
Improving startup time can involve minimizing imports, lazy loading modules only when needed, using compiled bytecode (.pyc files), and reducing global-level code execution. Tools like PyInstaller or caching techniques can help. Profiling startup with modules like py-spy identifies bottlenecks for optimization.
- What are Python’s built-in data types?
Python has several built-in data types including numeric types (int, float, complex), sequence types (list, tuple, range), text type (str), set types (set, frozenset), mapping type (dict), and boolean type (bool). These provide versatile containers and primitives to represent and manipulate data efficiently.
- What is the zip() function and how is it used?
The zip() function aggregates elements from multiple iterables, returning an iterator of tuples where each tuple contains one element from each iterable. It’s commonly used for parallel iteration or combining sequences, making it easy to process multiple data streams simultaneously.
- How can you create immutable objects in Python?
Immutable objects can be created by using built-in immutable types like tuples and frozensets or by defining custom classes that override attribute setters or use __slots__ to restrict dynamic attribute assignment. Immutability helps ensure data integrity and thread safety.
- What is Python’s Global Interpreter Lock (GIL) and its impact?
The GIL is a mutex that protects access to Python objects, preventing multiple native threads from executing Python bytecodes at once. While it simplifies memory management and avoids race conditions, it limits CPU-bound multithreading performance. As a result, multiprocessing or alternative implementations are used for true parallelism.
- How does Python handle function arguments like mutable and immutable types?
In Python, immutable types like integers, strings, and tuples cannot be changed after creation, so when passed as arguments, the function works with a copy of the reference but cannot alter the original object. Mutable types like lists and dictionaries can be modified inside the function, meaning changes affect the original object outside the function. Understanding this helps avoid unintended side effects.
- What are Python’s comprehensions and what types are available?
Python offers comprehensions as concise syntactic constructs to create collections: list comprehensions, set comprehensions, dictionary comprehensions, and generator expressions. These allow writing loops and conditional logic in a single line, improving readability and often performance by avoiding explicit loops and temporary variables.
- How do you manage memory leaks in Python?
Although Python has automatic garbage collection, memory leaks can occur through lingering references, especially in global scopes or cyclic references involving objects with __del__ methods. Profiling tools like tracemalloc and proper resource management using context managers help detect and prevent leaks, ensuring efficient memory use.
- Explain the concept of duck typing in Python.
Duck typing means Python focuses on whether an object behaves like the expected type (supports necessary methods/attributes), rather than its actual class inheritance. This allows flexible and dynamic code where the exact object type is less important than its behavior, enabling polymorphism without strict type checks.
- What is the use of the with statement and context managers?
The with statement simplifies resource management by ensuring that setup and teardown code is executed automatically, like opening and closing files. Context managers implement __enter__() and __exit__() methods to define these actions. This leads to cleaner, safer code by preventing resource leaks.
- How do you implement a singleton pattern in Python?
Singleton ensures a class has only one instance and provides a global access point. In Python, this can be implemented by overriding the __new__ method to control instance creation or using decorators/metaclasses. Although not commonly needed due to Python’s module system, it’s useful in scenarios requiring shared state or resource management.
- What is monkey patching in Python?
Monkey patching refers to dynamically modifying or extending code at runtime without altering the original source. This can involve replacing methods or attributes of classes or modules. It’s useful for quick fixes, testing, or extending functionality but should be used cautiously to avoid maintainability issues.
- How can you optimize Python code using built-in functions?
Built-in functions like map(), filter(), sum(), and any() are implemented in C and highly optimized. Using them instead of explicit loops can improve performance and readability. Also, list comprehensions and generator expressions are preferred for their speed and memory efficiency.
- What are Python’s iterators protocol methods?
The iterator protocol requires implementing two methods: __iter__() which returns the iterator object itself, and __next__() which returns the next item or raises StopIteration when exhausted. This protocol allows objects to be used in loops and comprehensions, enabling uniform iteration behavior.
- How do you handle concurrency in Python?
Python supports concurrency through threading, multiprocessing, and asynchronous programming. Threading is suited for I/O-bound tasks but limited by the GIL for CPU-bound tasks. Multiprocessing spawns separate processes for true parallelism. Asyncio uses event loops and coroutines to handle large numbers of concurrent I/O operations efficiently.
- What is the difference between is and == in Python?
The is operator checks if two variables point to the exact same object in memory, meaning it compares identity. In contrast, == compares the values or contents of the objects for equality. For immutable types like small integers and strings, both may sometimes behave similarly due to interning, but generally is and == serve different purposes.
- How does Python’s lambda function work?
A lambda function is an anonymous, inline function defined using the lambda keyword, capable of taking any number of arguments but consisting of a single expression. It’s useful for short, throwaway functions often used with higher-order functions like map(), filter(), or sorting key functions, improving code brevity.
- What are Python’s built-in modules for handling dates and times?
Python provides the datetime module to work with dates and times, offering classes for dates, times, datetimes, timedeltas, and time zones. It supports parsing, formatting, arithmetic, and comparison. Additionally, the time module deals with low-level time functions, and third-party libraries like pytz extend timezone support.
- Explain how you can serialize and deserialize objects in Python.
Serialization converts Python objects into a byte stream or string for storage or transmission, while deserialization reconstructs objects from this data. The pickle module handles general serialization of Python objects, whereas JSON serialization via the json module is used for interoperability and human-readable data. Care must be taken when unpickling due to security concerns.

